Zegami platform helps build unbiased data models
Zegami provides an image-based data visualisation platform designed to enable users to explore large image datasets in order to unlock insights and build machine learning models. The company points out that, with any system that is reliant on data, overall effectiveness is dependent on the quality of data that it utilises. If the data is good, the value of output will reflect this, and AI is no different. In machine learning-based models, when trained on incorrect, underrepresented or biased data, the models can themselves become biased.
“In the field of AI, we typically encounter five different types of bias: algorithmic, sample, prejudice, measurement and exclusion bias. These can be difficult to eliminate, particularly as certain biases may be unconscious,” states Zegami. “One example comes from an open-source dataset of melanoma from the International Skin Imaging Collaboration, where the initial images were from fair-skinned people. A growing body of work suggests cancer-detecting algorithms trained on these images are less precise when used on black patients, partly because these models have not ‘seen’ examples of cancer on darker skin types.”
 To avoid AI bias and its implications, it is necessary to train machine learning algorithms on reliable and representative data from the beginning. To maximise accuracy, it is essential to acquire enough real-world examples to produce training datasets that are diverse in demographics, clinical feature detection and other risk factors. Zegami can help with either curation of training data, explainability or validation of the AI models in development or in benchmarking the correct
To avoid AI bias and its implications, it is necessary to train machine learning algorithms on reliable and representative data from the beginning. To maximise accuracy, it is essential to acquire enough real-world examples to produce training datasets that are diverse in demographics, clinical feature detection and other risk factors. Zegami can help with either curation of training data, explainability or validation of the AI models in development or in benchmarking the correct
AI model to procure.
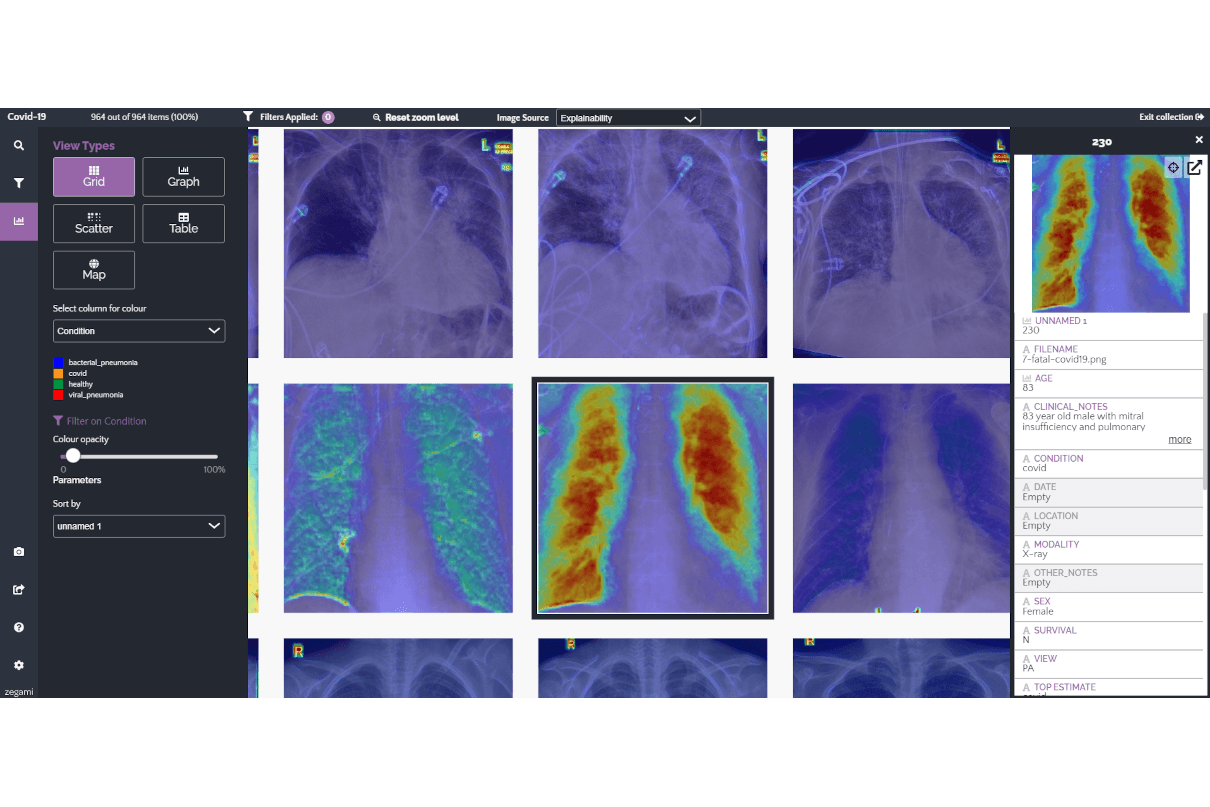
Lead picture: An example of how bias can be created when training a machine learning model. The model was trained on a dataset of lung images to try to identify COVID-19 in patients. However, all the images were taken from the same hospital and the model found a way to ‘cheat’, by focusing on image markers that had not been removed when cleaning the training dataset.
Published on page 19 of the October 2021 issue of RAD Magazine.